Netflix’s public claims suggest that, a large part of making a robust recommendations system for the users was building reliable, consistent feature pipelines not just tuning model architectures.
Photo by Thibault Penin on Unsplash
When we talk about MLOps, or Machine Learning Operations, we jump straight into the visible machinery: model registries, CI/CD pipelines, deployment strategies, and scalable inference. All crucial factors, but there is something else that silently dictates how fragile, expensive, and maintainable an ML system actually is — the feature set.
Every feature that is provided to the model as an input is a long-term commitment. It must be computed, stored, validated, versioned, monitored, and maintained between the training phase of a model and during inference. In many real-life use cases, this has to happen in real time and under tight latencies.
As the feature count grows, the training pipelines become more expensive, inference paths tend to break apart, and the system ends up depending on a web of data sources that were never supposed to work together.
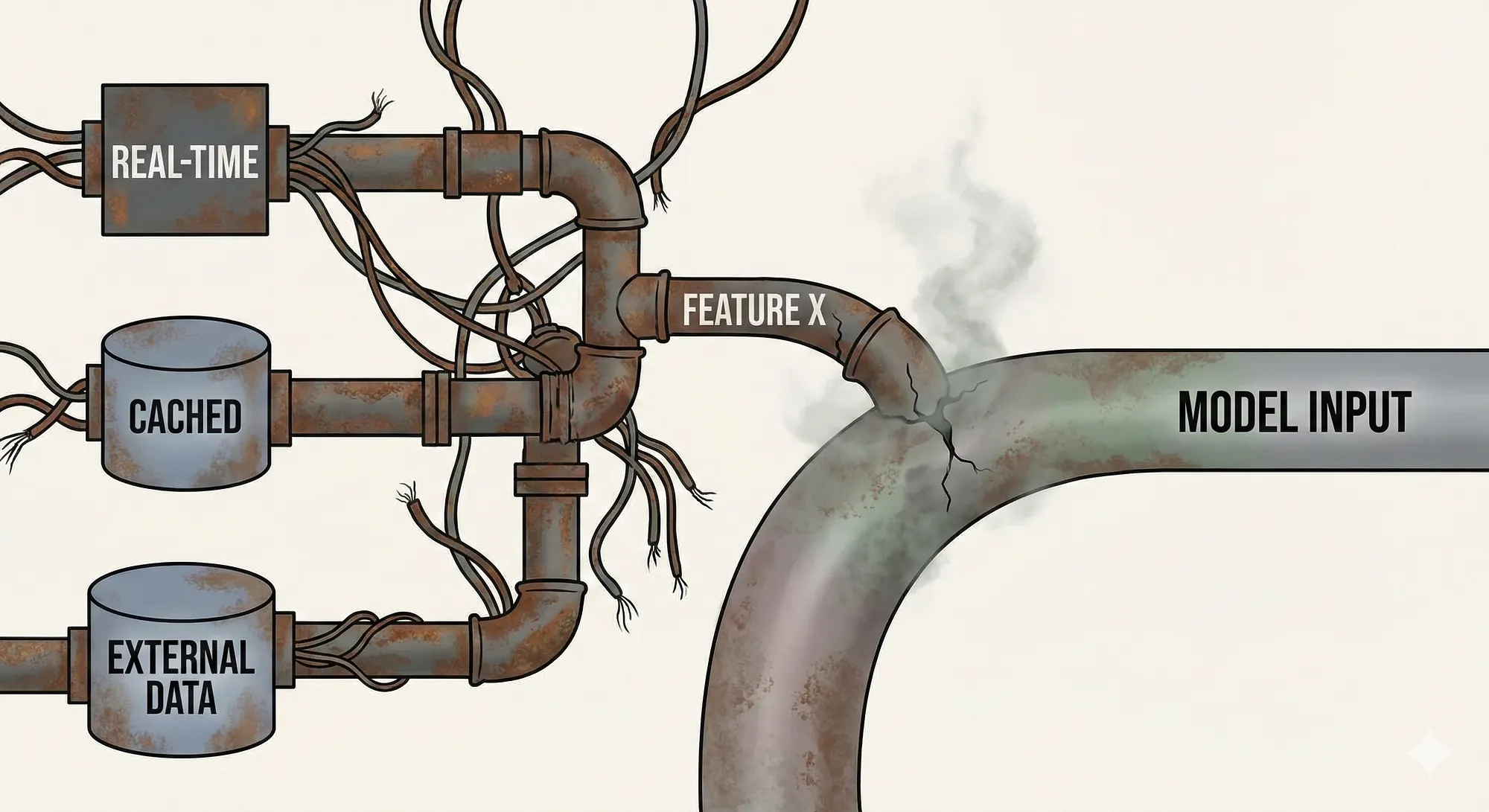
Models still return predictions, but the guarantee of the validity of these predictions comes under scrutiny in such circumstances.
This is why Feature Engineering is more than just a data preprocessing step in modern MLOps pipelines — which sketches the difference between a model that runs in a notebook and a model that actually runs in a production environment.
Notebook vs. Production
Feature engineering feels easy in a notebook — a few lines of pandas, some clever operations on the data, done. But the moment that feature goes live in a production model, you’ve made a silent promise: this will run correctly, every time, for every request, forever.
That’s where things get expensive — in terms of development time, infrastructure cost, and the stress of 3am incidents.
The real problem is that most developers treat features like sticky notes: written for one model, thrown away after. What they should be is more like a shared database: versioned, reusable, and accessible by any model that needs them.
The gap between those two approaches is exactly what turns a great notebook demo into a production system nobody wants to touch.And the worst part? The notebook still runs perfectly. The notebook always runs perfectly.
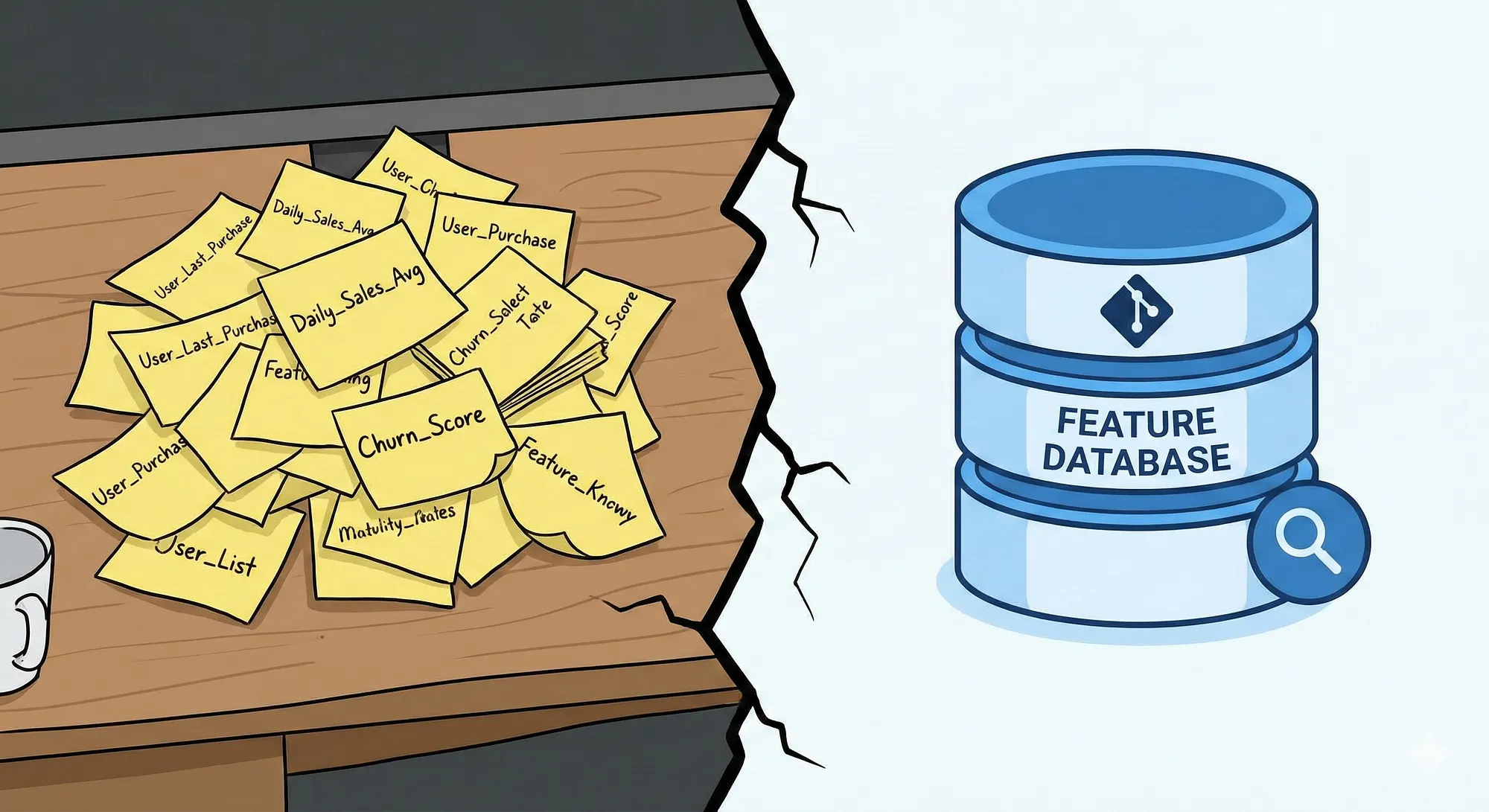
The Silent Failure
When it comes to Machine Learning and related domains, most people think that the major cause of failures in these domains is due to a flaw in the model architecture or a lack of resources and infrastructure. However, this is not the case for most real-world issues.
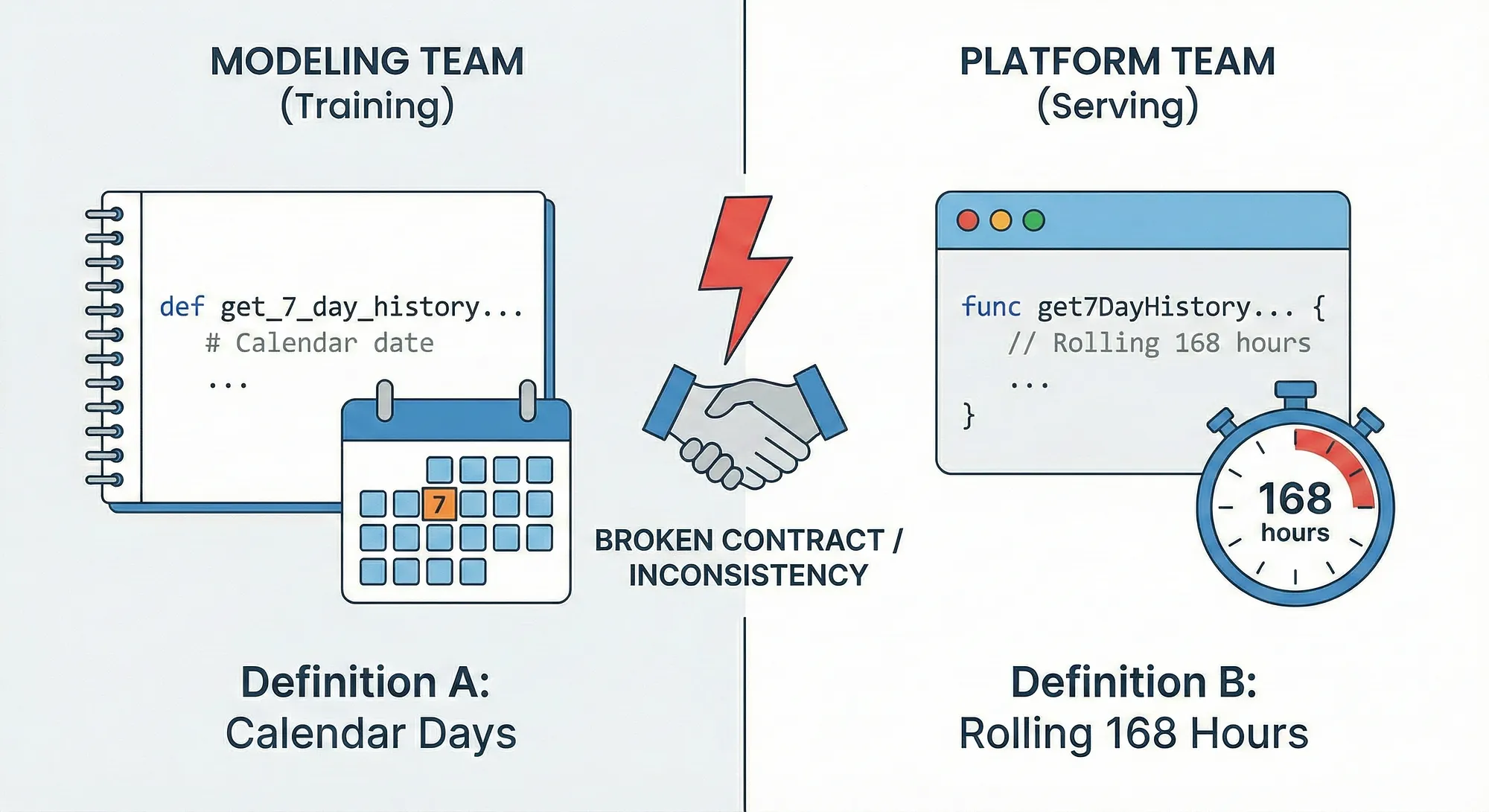
A large fraction of breakdowns are caused by something known as training-serving skew:** The model is trained on a set of features and served on another. This leads to a quiet collapse of the model’s performance while the system appears healthy on the outside.
Imagine Netflix trains its recommendation models on a feature — ‘titles watched in the past 7 days’ — during training. Now, in production a different team or a developer working on the same system provides the data in a format where their version of 7 days means ‘168 rolling hours’. Now, both interpretations are reasonably correct but cannot be considered the same as one is grouped by the calendar date, while the other depends on the total time spent.
It gets worse. Offline, during development, engineers might accidentally include data that wouldn’t exist at prediction time — like using a user’s total viewing history to predict what they’ll watch next, when in reality you’d only know what they’ve watched so far. The model looks great on paper. Then it goes live and underperforms, and nobody immediately knows why.
The model didn’t break. The data quietly drifted. And the system had no way to tell you.
The Organizational Problem
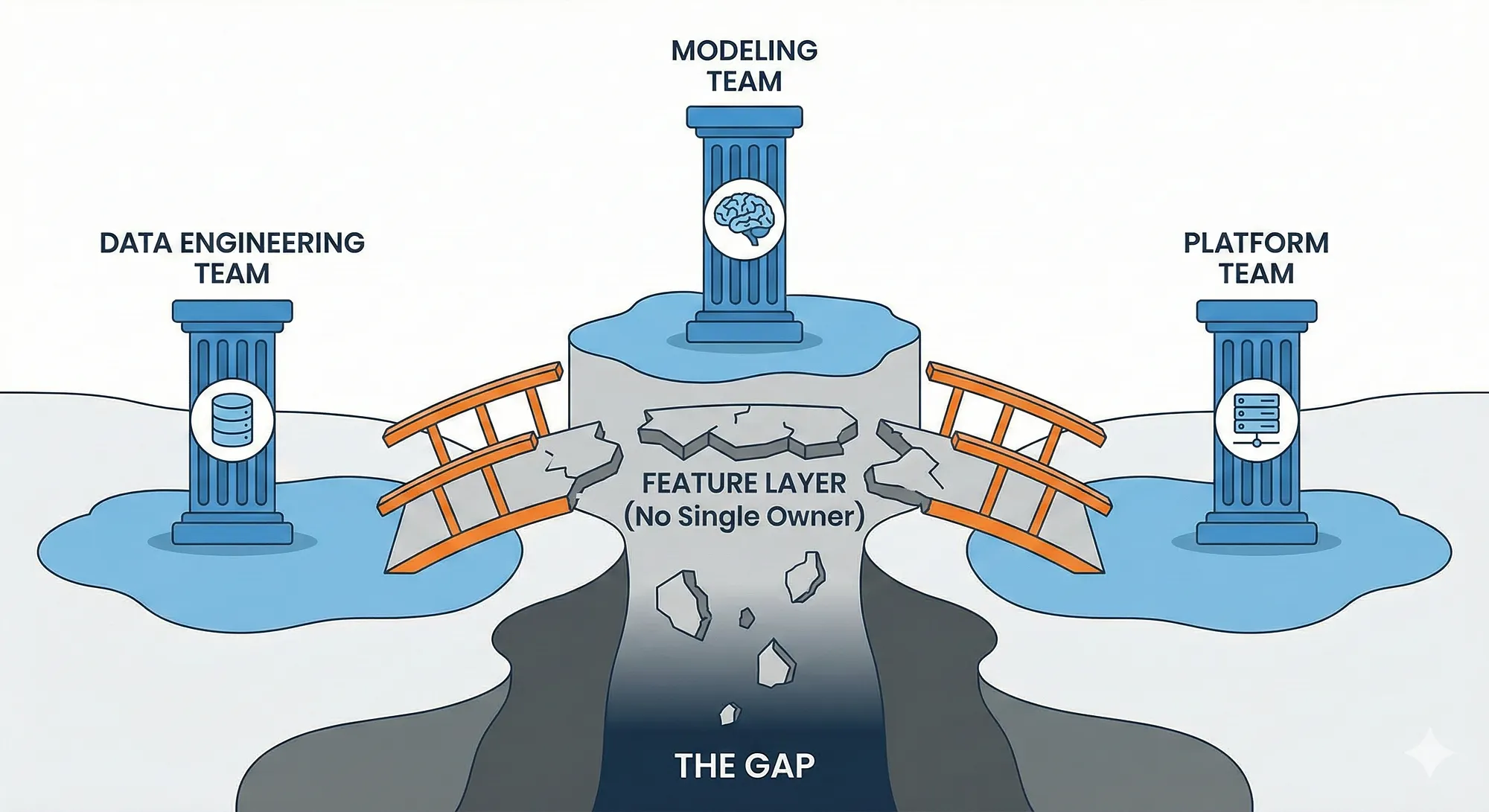
Another major point of failure that rarely appears in post-mortems is the way the feature layer is structured in organizations.
In most organizations, the feature layer has no single owner/maintainer. A data engineering team produces raw summaries. A modelling team borrows them and wraps them in feature logic. A platform team manages the serving infrastructure. Nobody explicitly owns the contract between these different teams. This is how you end up with a ‘7 day watch history’ that means one thing in the training pipeline and something slightly different but logically the same in the production environment and maybe some other variants of the same feature across multiple repositories.
The failure is caused due to the gaps rather than the incompetence of an individual or a team. Every contributor is doing their job correctly but the system ends up broken anyways.
This is also why the problem compounds silently. When features are defined per-model, buried in notebooks or private repos, they are invisible to the next team that needs something similar. Discovery is hard, so duplication is the easiest path. Those duplicates drift. Some break. None of them have a clear owner when they do. And because every breakage looks like a data issue or a model issue on the surface, the underlying organizational dysfunction never gets formally identified or fixed.
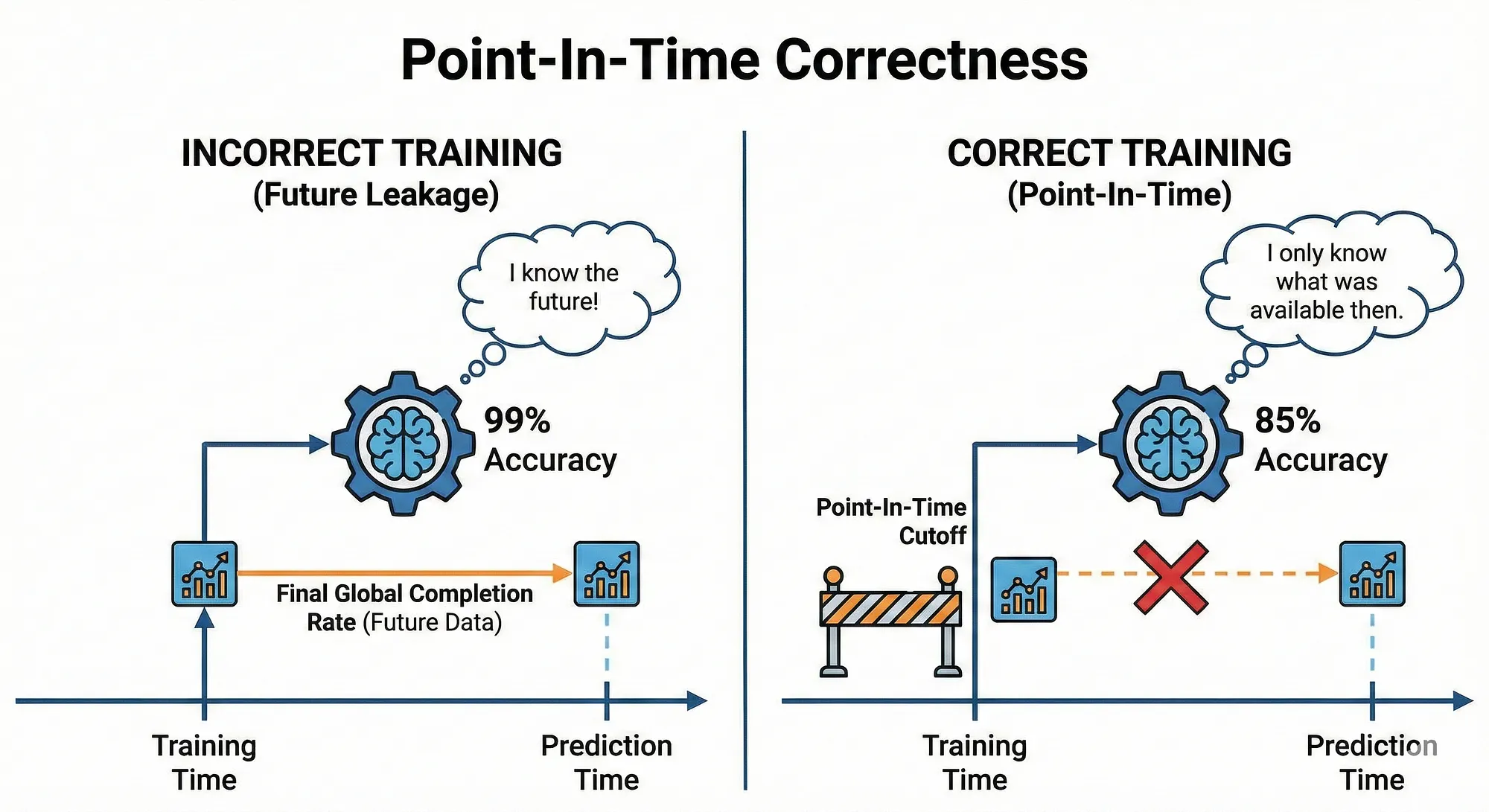
Point-In-Time Correctness and the Deja Vu Nightmare
Even if you perfect your training and serving logic in a production environment, something can still go terribly wrong with the system.
Imagine Netflix is building a model to predict whether a member will finish watching a new show within its first week of release. The training data includes viewing hours, engagement signals, and accidentally — the show’s final global completion rate, which only exists after that week has passed.
During training, the model quietly learns: “Shows with high global completion rates get finished.” In production, that metric doesn’t exist yet — the show just dropped.
Point-In-Time Correctness is the principle that fixes this at the root. It states that every training example must only contain feature values that would have been genuinely knowable at the exact moment that prediction would have been made in the real world.
The really painful part comes when you try to fix it. Unlike a regular software bug where you patch the code and move on, here you have to go back and recompute months or years of historical data with the corrected logic. That’s called a backfill, and it’s expensive, slow, and risky.
This is precisely why modern feature stores implement temporal joins — a mechanism that automatically ensures every feature value retrieved for a training example corresponds to its correct historical timestamp.
The Iceberg
The problems described above — training-serving skew, organizational pitfalls, and point-in-time leakage — are just the tip of the iceberg. In a production ML system at any meaningful scale, these issues compound.
The good news is that the ML community has spent a better part of the last decade in overcoming these issues and building some solutions around them. Now, these solutions aren’t some kind of magic or rocket science, but at least they get the job done!
- Feature Stores: The most direct answer to both training-serving skew and organizational silos is a feature store — a centralized system that handles the computation, storage, and serving of features in a way that is consistent across training and inference. A feature is defined only once in a feature store and can be accessed by various teams during various processes along the pipeline ensuring robustness.
- Feature Versioning: The features used in a ML system must be treated like actual codebases — versioned and well documented. Whenever a feature definition changes, any model or any workflow depending on the modified feature should be notified or pinned behind a version tag which can ensure data quality, and prevent hours of debugging.
- Feature Monitoring: Even with a feature store and version control in place, the work is not done. Features can still drift. A data source that fed your pipeline cleanly six months ago might now return nulls silently, change its distribution as user behavior shifts, or degrade in freshness. The model keeps serving predictions. The predictions get quietly worse.
Features Are a Systems Problem
There is a tendency in ML to treat feature engineering as a data problem — something that lives in the domain of data scientists and gets resolved before the “real” engineering begins.
Every feature in a production ML system is a long-running contract between the data layer, the training pipeline, and the inference. It must be computed correctly, served consistently, versioned carefully, and monitored continuously — for as long as the model that uses it is still running and providing inferences.
A model that runs in a notebook is a proof of concept whereas a model that runs in production is a system.